Right before Latin emerged as the dominant language on the Italian peninsula and beyond, Etruscan was one of the major languages in the Mediterranean. It seems to have belonged to the Tyrsenian language family and while its family members were also spoken in across the Alps and on one or more islands in the Aegean Sea, all Tyrsenian languages went extinct. Despite over 13,000 inscriptions spread across the Mediterranean, the Etruscan language is still quite poorly understood. Basically, as the Roman state gobbled up most of the Etruscan speaking land, Latin started outcompeting other languages and at some point during the 1st century BCE, the population of the region was probably completely Latinized.
It is rather common that languages that go extinct as a result of language shift imposed by other cultures become more or less forgotten. However, Etruscan’s demise at the expense of Latin has paradoxically preserved parts of the language in the form of loan words that were borrowed from Etruscan into Latin before Etruscan ceased functioning as a spoken language. During the following centuries, Latin happened to become the dominant language in Europe, first as a result of geographical extent, then as a liturgical language, as well as the language of education and science.
From the 17th to the 19th century, one of the child languages of Latin, French, then took Latin’s place and spread even further due to colonialism, which is why we use the term lingua franca for languages used for communication between people who do not share a native language. In addition, French have had a remarkable influence on English vocabulary, and English happened to, in turn, become the global language of today. Consequently, Etruscan loanwords that entered Latin more than two thousand years are still widely used today in hundreds of languages. Here are some examples:
autumn from Middle English autumpne, from Old French automne, autonne, from Latin autumnus, probably from Etruscan 𐌀𐌕𐌖𐌍𐌄 atune ‘autumn’
mundane from Middle English mondeyne, from Old French mondain, from Latin mundus ‘world’, probably from Etruscan 𐌌𐌖𐌈 muθ ‘pit, mundus’
palace from Middle English paleys, from Old French palais, from Latin palatium (in reference to the Palatine Hill, one of the seven hills of Rome), which might be named after the Etruscan goddess of shepherds, flocks and livestock, Pales
person from Middle English persone, from Old French persone, from Latin persōna ‘mask’, probably from Etruscan 𐌘𐌄𐌓𐌔𐌖 phersu ‘mask’
Rome from Middle English Rome, from Old English Rōm, Rūm, from Proto-Germanic *Rūmō, from Classical Latin Rōma. Probably ultimately from Romulus, one of the mythological founders of the city, which might have been named after Etruscan 𐌓𐌖𐌌𐌀 ruma, from 𐌓𐌖𐌌 rum ‘teat’
Several of these words, however, could have other etymological sources, such as Ancient Greek, but it is reasonable to assume that at least some of these words are solely of Etruscan origin.
When I was a child in the mid-90’s – before communication over the internet was widespread – I used to be pen pals with some of my Finnish cousins and friends. I sometimes received letters addressed to “Sandra Gronhamn”, which is a misspelling of my Swedish last name Cronhamn, pronounced with an initial [k]-sound. I also noticed that my Finnish relatives tended to not just spell, but also pronounce, our last name with a [g]. It wasn’t until I started studying linguistics many years later that I understood what was going on.
What my Finnish relatives were doing is called hypercorrection in technical terms. It’s a sociolinguistic phenomenon where a linguistic pattern is overapplied due to unfamiliarity with its distribution in the language or linguistic register in question. Hypercorrection should not be written off as errors or incompetence, however – it’s a very interesting phenomenon which actually stems from a quite deep awareness (even if subconscious) about differences in phonological and grammatical patterns. Hypercorrection also sheds light on the intricate processes and effects of language contact.
Hypercorrection can take place between separate languages, as in the example above about Finnish speakers pronouncing or spelling a Swedish name. In fact, this example is part of a broader pattern. Finnish lacks so-called voiced stops (the sounds [b, d, g]) in native vocabulary, and in early loanwords from Germanic languages, these were replaced by their voiceless counterparts [p, t, k]: Swedish bädd ‘bed’ was borrowed as peti, and gata ‘street’ as katu. Slowly but surely, however, the voiced stops sneaked their way in to the Finnish phonological system through long-standing language contact. [b] is now its own phoneme, since it contrasts with [p] in minimal pairs like baletti ‘ballet’ and paletti ‘palette’.
This provides the background to Finnish hypercorrection of voiced stops in languages like Swedish and English (which they are all more or less familiar with since they learn both in school). They become aware of the fact that [p], [t] or [k] in a Finnish loanword often corresponds to [b], [d] and [g], and since this sounds less Finnish, they sometimes overapply this pattern – even in cases where [p], [t] and [k] actually correspond to [p], [t] and [k]. This happens not only in Cronhamn > Gronhamn, but also in e.g. biisi ‘song’, which is from English piece. Another example is the Finnish 70’s rock back named Hurric… no, sorry, Hurriganes.
Cover of Hurriganes’ debut album (picture via Wikimedia Commons)
Swedish speakers also engage in hypercorrection, for instance in the pronunciation of some French loanwords. Most Swedes have at least a vague acquaintance with French pronunciation, for example that they tend not to pronounce consonants towards the end of a word. This assumption, which is only partially true, explains the fact that entrecôte is pronounced without the final [t] in Swedish, despite the fact that the [t] is pronounced in French. To Swedish speakers, it simply sounds more French to skip it.
The examples we’ve seen so far have all had to do with phonology, i.e. sound patterns. But hypercorrection can also target grammar. For example, English speakers tend to overgeneralize certain plural forms which are borrowed from classical languages. Sometimes, octopuses (in the plural) are referred to as octopi, assuming that it is a Latin word following the same pattern as e.g. alumnus–alumni. Octopus is indeed borrowed from Latin, but it is of Greek origin, and the Latin plural form is octōpodēs.
Hypercorrection does not need to operate across language boundaries – it also commonly occurs between different registers of the same language. For instance, speakers of what is perceived as a less prestigious dialect may hypercorrect certain patterns in their own speech to something which is associated with a more prestigious variant. An example from English is the pronunciation of umbrella as umbrellow, in analogy with fellow, which is perceived as a more standard pronunciation than colloquial fella.
Why do we hypercorrect? Quite simply, we like to generalize things, and if for instance a Swedish speaker applies the rule ‘do not pronounce consonants towards the end of a word’ to French pronunciation, they may produce correct pronunciations 99% of the time. As such, it is a viable strategy. Hypercorrections constitute the small portion of unsuccessful attempts at applying a rule – however, without them, we may not have noticed the rule in the first place.
There has been a growing global awareness of the loss of linguistic diversity since the end of the twentieth century. The number of projects in which a linguist travels to a rural community to document a language in danger of extinction has increased in the last two decades. Language documentation (LD), despite its twenty-five-year history, is still a relatively unknown discipline. Linguist Peter Austin points out that language documentation is supported by international academic journals, specialized conferences, and various training centres around the world (see here). Today, we’ll look at some of the methods and goals of this linguistics subfield.
The belongings of a field linguist provides some clues about what the job is like. The equipment typically includes a recorder and various types of microphones: one of the goals is to make recordings of a language for which documentation is scarce or non-existent. Such recordings are likely to be the only ones ever made, so it is crucial that they are of the highest possible quality. The equipment also includes a video camera, a computer, and various hard drives that store backups of valuable recordings. But this is not entirely new: before the emergence of language documentation, anthropologists and linguists were already travelling to remote communities to record and research languages. So what has actually changed with documentary linguistics?
According to one of the most influential documentation manuals, the main goal is to create a representative, multipurpose, and long-lasting record of a language. To achieve representativeness, the linguist collects samples of different types of communicative events of a community’s daily life. These events may include conversations, stories from the past, traditional tales, songs, and riddles may be included, as well as descriptions of local plants and animals, or instructions on how to weave, build a house, or fish. Some projects focus preserving community-specific register, such as the epic Hudhud chants of the Ifugao (Philippines), which can run for hours and are recounted by heart, or the instrumental and whistled speech registers used by the Gavião (Brazil), which imitate the language’s sounds.
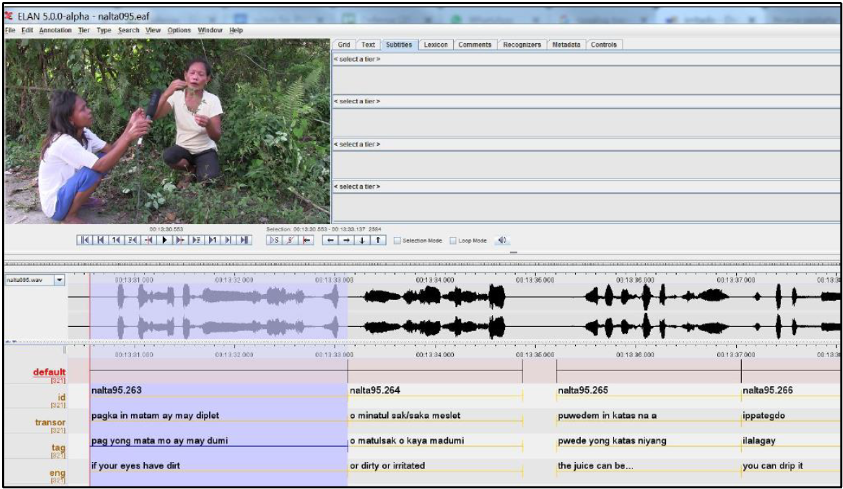
In terms of multifunctionality, the recordings must be able to be used by a variety of persons with a variety of intents and purposes. For this reason, priority is given to the collection and dissemination of primary data, i.e., unprocessed data, collected directly from the community of speakers. For this purpose, a substantial part of the fieldwork time is dedicated to annotating recordings, a process in which the constant supervision of a native speaker is needed. The most basic form of annotation entails segmenting each recording into sentences and adding a transcription and a translation into English. Such annotation allows users without prior knowledge of the language to understand the content of the recordings, and also to research and cite them. The set of recordings collected and annotated by a linguist is referred to as an “annotated collection” or “language documentation corpus.”
Screenshot of an annotated recording of the Northern Alta language (Philippines), with sentence reference number, transcription and translations to Tagalog and English.
Back at home, the linguist uses the collection to conduct a systematic investigation of the language to create a grammatical description. Simultaneously, the collection is prepared to be uploaded into one of the DELAMAN archives, a network dedicated to primary data and endangered languages. For example, archives like ELAR (Germany), TLA (Netherlands), or RWAAI (Lund University), play a key role in language documentation: they promote access to the collections, and more importantly, they assure their long-term preservation so that future users can access them. Note that if we browse the catalogues in these archives, it may seem as if a lot of documentation has been completed, but there is a lot more to do! There are many languages that need documentation, and nowadays, previously unknown languages are still being identified, as with Jedek, an Austrosiatic language spoken in Northern Peninsular Malaysia.
On the other hand, many languages for which an annotated collection has been produced have only been partially investigated, given that many projects are confined to producing a grammar and a lexicon of the language. Linguist Lawren Gawne encourages other linguists to work with her collection, in a guide to the Syuba language documentation corpus (Nepal), and outlines which aspects of language are left to be researched. She also specifies which parts of the collection can be used by anthropologists or historians, and also states that the material is of sufficient quality for filmmakers to exploit, as demonstrated in this showreel Finally, Gawne emphasises that language speakers are the most significant users of her collection. The annotated collection, along with the grammar, can be used to create instructional materials that could aid in the language’s transmission. Furthermore, future generations of the Syuba community will be able to view the video catalogue of their ancestors at their leisure, thanks to the role of language archives.
Language documentation has had a favourable impact on different fields of knowledge since its inception. For example, a master’s or PhD student could be able to use an LD corpus to write a dissertation on a specific language. It also enables academics from different locations or times to access an annotated collection and verify or refine linguistic analyses. The latter point is not only beneficial, but vital: despite the fact that each language represents a vast universe of knowledges, most languages are documented by a single linguist—or a small team for the lucky ones. Consider the number of linguists working on English or French, for example. In comparison, how much could a single individual accomplish? Here is one of the most important contributions of language documentation: it intends to promote and aid different kinds of users in navigating through such universes, whereas in the past, linguistic data was often collected for a specific reason and was rarely shared.
References
Austin, P. (2015). Language documentation 20 years on. In M. Pütz & L. Filipovic (Eds.), Endangerment of languages across the planet (Amsterdam:, pp. 147–170).
Gawne, L. (2018). A Guide to the Syuba (Kagate) Language Documentation Corpus. Language Documentation & Conservation, 12, 204–234.
Gippert, J., Himmelmann, N. P., & Mosel, U. (Eds.). (2006). Essentials of Language Documentation. Mouton de Gruyter.
The very concept of ‘secret’ languages appears as if it is taken out of a novel. We automatically think of military codes, inmate jargons or suburban youth slang. However, cannot all languages be ‘secret’ if they represent a shared code used by a closed network and unintelligible to outsiders? This is of course true in many instances: minority languages, immigrant languages, local languages or dialects, youth jargons, or ethnolects – all these represent communication systems that can, under certain circumstances, be restricted to a closed network of speakers and not shared by outsiders. So what makes a language a ‘secret’ language? This is the topic of this blogpost.
First, a secret language is no one’s mother tongue – this is probably the most important distinction from a ‘normal’, non-secret language. Secret languages represents different types of jargons that are sustained within a closed network. Jargons are often connected to an occupation or a lifestyle, but they may also be varieties of a distinct group, that share both a life-style, an ethnicity, and a prototypical occupation. Jargons are often transferred from father to son, together with the occupation or the life-style, the purpose of which was not just to keep outsiders, but also sometimes members of the own family, outside. Secret languages of this type, connected to various occupations, are found in the Eurasian continent as well as in Africa and South America. They are often the idiom of occupations with a distinct social function, most typical occupations that are excerpted within the society but which have with a special, often low, status. In Europe there are several traditional occupational jargons, including the language of pedlars, dealers, chimney sweepers, or circus people. In pre-industrial society, various types of low-status occupations, such as the executioner’s henchman or skinners, used to have their own secret jargons. In Africa, to mention an example, we have documented secret languages among healers, skinners, and sandal flickers. A general problem of these secret languages is that they are often not written down and therefore remain a mystery.
Generally, secret languages share some common features. They do not have a grammar system of their own, like ‘normal’ languages. Their grammatical system relies on the grammar system of another language, typically the majority language of the country where the languages reside or a previous majority language. This grammar is often simplified and syntactic patterns can be replaced by pidgin-like structures, such as ignoring or reducing grammatical morphology, simplified phonology, and SVO word order. A phenomenon is to borrow the ‘appearance’ of a language, by means of stress patterns, prosody, dialectal variation and gestures, but to switch all content words, sometimes the entire lexicon. This makes secret languages more similar to mixed languages, which take the grammar from one language and the lexicon from another. The lexicon in a secret language can be taken from a language different from the grammar language, but it is often an ad hoc-conglomerate of words from various adjacent source languages. Very often, secret languages ‘distort’ their lexicon by various complex patterns of morphological transformation; for instance, they truncate words and add heavy suffixes, they reverse syllables or letters, or they add epenthetic vowels within words. The result is a language that ‘melts in’ – from distance it appear as if speaker use a native or indigenous idiom, but not one single word is understandable to the environment.
On Scandinavian soil, there are several traditional secret languages. One is the pedlars’ language, which in fact is two, one in the isolated county of Dalecarlia, Gråmål ‘grey language’ or Monsing, the main pedlars’ secret language, which during the 20th ct. transformed into a prisoners’ language. The vocabulary of Monsing is based on multiple languages. Many words are borrowed from Scandoromani, the language of the indigenous Swedish Romani speakers, other words are from Low German, Rotwelsch, the Medieval secret jargon of European outsiders, from Finnish, Russian, as well as from Swedish. Swedish loans are totally changed by linguistic distortion. Sources of Monsing go back to the 17th century and they give us a glimpse of the type of communication that Monsing speakers had. Besides communication related to their occupation, much of the content is rude, such as talk is about the farmers (who are supposed to be stupid) and in particular their wives and daughters (who are target of their sexual interest). Even though there are no ‘real’ speakers of these languages in Sweden anymore, Monsing is still, together with Scandoromani and Knoparmoj, the secret language of chimney-sweepers, a very important source for words in the Scandinavian vernacular languages.
Example of distorted language in Monsing, the language of pedlars:
Languages differ in what information can be conveyed through grammatical rules and what people in different speech communities talk about. While many languages use a subject-verb-object word order, such as Mary pets the cat, other languages use a Yoda-like object-subject-verb word order, such as the cat Mary pets, and conversations about growing mangos tend to be more frequent in tropical regions than in arctic regions. However, even basic perceptual notions vary greatly across languages and cultures both in detail and in scope. For example, despite the fact that humans are, on average, able to perceive the same range of the light spectrum, some languages only have two color words, basically contrasting brighter colors with darker colors (Kay & Maffi, 1999), while others have very large inventories in which every color word can be modified according to brightness and saturation. Such differences gave rise to something called linguistic relativity, that is the thought that the structure of a language affects its speakers’ worldview and/or cognition. One commonly cited but incorrect example is that Inuit languages would have exceptionally many words for snow and ice as a result of living in very cold environments. Even though the literal interpretation of linguistic relativity, also called linguistic determinism, was popular during the early 20th century, it has since been disproven. But are there many other, more nuanced, linguistic patterns that can be attributed to the surrounding world.
One common way of dividing cultures is distinguishing between rural and urban ones. Rural societies are characterized by lower population density in which the most important economic activities involve the production food and raw materials in a somewhat natural environment. Urban societies, on the other hand, are characterized by higher population density and an environment that provides basic facilities for human activity. Another way is to divide cultures between sedentary agricultural societies, which would apply to all societies in which the economy is based on producing and maintaining crops and farmland, and hunter-gatherer societies, which refer to societies that get most of their food by hunting wild animals and gathering edible wild plants. The lifestyles resulting from these conditions naturally affect what people tend to talk about, which cultural artifacts are regarded as important, as well as certain social structures. However, these differences also seem to have some interesting effects on how the actual structures of languages are shaped.
Spatial relations used to convey direction based on the left and right sides of one’s body might seem fundamental, but these egocentric frames of reference are only common in industrialized and urban speech communities (Levinson, 2003; Palmer, 2015, Nölle et al., 2020). In rural speech communities, referentiality is often based on the fixed properties of the local environment, such as uphill–downhill in mountainous areas, and are thereby viewpoint-independent. In Marshallese, which is spoken mostly on the atolls of the Pacific, oceanward and lagoonward are used. However, Marshallese speakers that have moved abroad to inland areas use the egocentric left–right reference frame instead (Palmer et al., 2017). Languages also differ in how many words for different smells they have, which makes odor naming easier in some cultures (Majid, 2021). Many industrialized, urban speech communities only have a limited set of actual terms for smell, such as English stinky, fragrant, and musty, that is terms that do not directly derive from another word, such as English earthy or peppery. Larger inventories of actual smell terms occur more frequently in hunter-gatherer societies, but also in pastoral and horticultural communities. For example, Jahai [jeha1242], has 12 such basic terms (Majid & Burenhult, 2014). The reason for this seems to be a combination of ecology (people living in industrialized environments are exposed to air pollution, while those living in dense tropical rainforests are exposed to greater biodiversity and high humidity), culture (city dwellers spend a lot of their time indoors, while hunter-gatherer communities spend their time moving around and interacting with the natural environment) and genes (it is possible that there might be some genetic differences in how many functioning olfactory receptors different populations have).
Spatial relations and smell terms represent only a fragmentary part of our vocabulary regardless of language, but there is one general example of how our way of life can affect how we talk. Some speech sounds are very common throughout the world, but there are also many specific sounds that are incredibly rare. [m], [i], [k] and [j] occur in over 90% of the world’s languages, while the sound used to “blow a raspberry”, [r̼] or [ʙ̺], is only used as a speech sound in, at most, a handful of languages (Moran & McCloy, 2019). Most distributions of speech sounds vary unevenly across the globe, either because languages which are related to each other tend to have inherited some common speech sounds or because of language contact between (related and unrelated) languages which causes linguistic features such as speech sounds to spread across geographical areas. For example, the typologically rare click sounds almost exclusively occur in Southern Africa.
This brings us to labiodental consonants, such as [f] and [v]. These sounds are articulated using the lower lip and the upper teeth and are neither common or uncommon, occurring in 44% and 27% of the world’s languages respectively. However, they are incredibly rare in languages spoken by hunter-gatherer societies, while rather common in food producer societies (Blasi et al., 2019). Since the hunter-gatherer societies of the world are geographically dispersed and speak a plethora of unrelated languages, neither areal nor genetic reasons can explain why this is the case. One of the unique properties of labiodentals is that their articulation depends on our so-called bite configuration – we need to be able to place our upper teeth on our lower lip to pronounce them. Try to pronounce [f] at the same time as you shift your lower jaw forward. Pretty difficult! While human children are generally born with a slight overbite, which makes pronouncing [f] and [v] an easy task, paleoanthropological evidence suggests that due to the extensive chewing of though food, Neolithic people’s overbites transitioned into an edge-to-edge with age. When societies started using agriculture and intensified food processing, their food became softer and the overbite persisted into adulthood, such as in most non-hunter-gatherer societies today. Consequently, since it is thought that modern hunter-gatherers live in societies which are somewhat similar to those of our ancestors when it comes to sustenance, the likely explanation for the remarkably specific geographic distribution of labiodentals is based on what people eat!
References
Blasi, D. E., Moran, S., Moisik, S. R., Widmer, P., Dediu, D., & Bickel, B. (2019). Human sound systems are shaped by post-Neolithic changes in bite configuration. Science, 363(6432), eaav3218. https://doi.org/10.1126/science.aav3218
Kay, P., & Maffi, L. (1999). Color appearance and the emergence and evolution of basic color lexicons. American anthropologist, 101(4), 743-760. https://doi.org/10.1525/aa.1999.101.4.743
Levinson, S. C. (2003). Space in Language and Cognition: Explorations in Cognitive Diversity. Cambridge University Press.
Nölle, J., Fusaroli, R., Mills, G. J., & Tylén, K. (2020). Language as shaped by the environment: Linguistic construal in a collaborative spatial task. Palgrave Communications, 6(1), 1–10. https://doi.org/10.1057/s41599-020-0404-9
Palmer, B. (2015). Topography in language: absolute frame of reference and the topographic correspondence hypothesis. In: R. De Busser & R. J. LaPolla (Eds.) Cognitive linguistic studies in cultural contexts (pp. 325–347). John Benjamins Publishing Company, Amsterdam.
Palmer, B., Lum, J., Schlossberg, J., & Gaby, A. (2017). How does the environment shape spatial language? Evidence for sociotopography. Linguistic Typology, 21(3), 457–491. https://doi.org/10.1515/lingty-2017-0011
In a previous post I discussed reduplication, with a particular focus on Austronesian languages. If English were to have such grammatical features, it would allow for structure like child-child to encode ‘many children’ (mimicking Indonesian reduplication) or I ta-talk to encode ‘I am talking’ (mimicking Bunun reduplication). Another amazing linguistic feature that English lacks is Echo Reduplication, which is the topic of this post.
Taking Hindi (Indo-European) as our starting point, we find the word shaadi, meaning marriage. The echo-reduplicated form derived from this stem is shaadi-vaadi, meaning ‘marriage, etc.’ or ‘marriage and such’. This grammatical feature differs from the other types of reduplication in that the reduplicant must change its phonological form. In the example above, sh- (pronounced ʃ) is replaced by v-. This is a productive process in Hindi and it can be applied to all major word classes. For instance, the verb likhnaa ‘write’ becomes likhnaa-vikhnaa ‘to write and such’, and the adjective moʈaa ‘fat’ becomes moʈaa-voʈaa ‘fat, etc.’. This process also applies to more recently borrowed English words, giving us amazing structures like pen-ven ‘pen, etc.’, ʈaim-vaim ‘time etc.’ and noʈis-voʈis ‘noice, etc.’.
This word formation process found throughout many of the languages of South Asia, although the exact details differ between languages. Kannada, a Dravidian language spoken in southern India, replaces the first consonant and vowel with gi- in echo reduplication (the vowel is long if the stem has a long initial vowel). We thus get examples where pustaka, meaning ‘book’, becomes pustaka-gistaka, meaning ‘books and related stuff’ and baagil, meaning ‘door’, becomes baagil-giigil ‘door and related things’. Like in Hindi, this also applies to other word classes, giving us amazing structures where doɖɖa ‘large’ becomes doɖɖa-giɖɖa ‘large and the like’, and ooda ‘run’ becomes ooda-giida ‘run and related activities’. The reduplicated forms behave grammatically like their unreduplicated counterparts. For instance, echo nouns can be objects in sentences (just like other nouns), exemplified in the sentence baagil-giigil-annu much-id-e door-ECHO-ACC close-PST-1s ‘I closed the door and related things’. The same holds for echo verbs, which take on the function usually taken on by verbs, as in the sentence ooda-giidabeeɖa run-ECHO PROH ‘Don’t run or do related activities!’.
If English were to have such features, we would be able to create wonderful sentences like I am cleaning the tables-vables with the meaning ‘I am cleaning the tables and such things’ and I am running-ginning with the meaning ‘I am running and doing related activities’!
Many linguists are also fan of maps, which can be a very neat tool to illustrate areal phenomena. Many maps are also easily accessible to non-linguists. For instance, the past years popular ‘etymology maps’ of Europe have been circulating the web, illustrating the distribution of a different roots for a certain concepts, e.g. camels, cucumbers, garlic etc.
Of course, maps, like any visual representation, can be deceptive. Common criticisms of these maps include e.g. de-emphasizing the presence of a minority language, in some cases over-emphasizing it. Sometimes they use state borders instead of linguistic borders, and languages with no clear geographical borders sometimes are not represented at all.
Nevertheless, I have been intrigued by linguistic maps for as long as I have been interested in linguistics, and I was part of etymology map trend from the very beginning. Already then, I noticed that mapmaking can be quite a tedious task. If you already had e.g. a map of Europe with the defined linguistic areas, would it not be possible to let a script color the map for you, just by feeding it the data? That way, you could spit out etymology maps of hundred of food etymologies in no time.
I started looking at ways in which the coloring part of the map could be automated. This post will serve as some inspiration for automated mapmaking for map-interested linguists. I will use a few lines of programming in Python, and some mapmaking in Inkscape. I am a linguist, not a programmer, so I apologize in advance for my crude code and explanations.
Creating a basemap
I started by creating a map with linguistic areas, which we will feed with spreadsheet data later. I made my basemap in SVG format, a vector format where the image is made up by geometry rather than pixels, because then the graphic can be edited through programming and has very high quality.
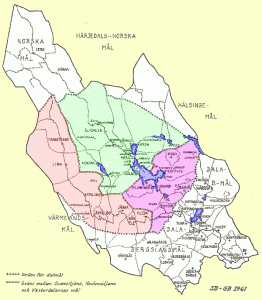
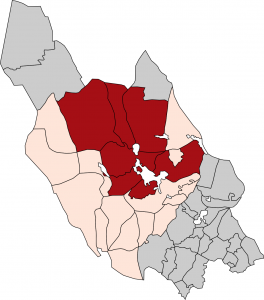
My basemap is of the Swedish region of Dalarna. I made it in Inkscape (like Photoshop, but for SVG) by tracing an older map of the parishes (Sw. socknar) of Dalarna – the parishes will serve as linguistic areas. In my SVG file, each parish is a path object, a geometrical shape, and in Inkscape you can give a unique ID to each object, so each parish has received a parish code in the SVG map below.
Parishes of Dalarna (older map) [source]My SVG version of the the older map.
Creating the spreadsheet with data
Next, I made spreadsheet of the data that I want to illustrate. I have chosen two features:
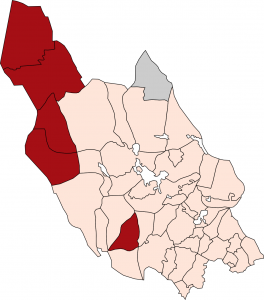
(1) fortition of older *hw > gv, kv, e.g. *hwass ‘sharp’ > Lima gvass (but Älvdalen wass) (2) loss of initial *h, e.g. *hesst ’horse’ > Orsa esst (but Nås hässt).
Therefore, my spreadsheet will have this structure:
parish
parish_code
hw-fortition
loss_of_h
Älvdalen
2392
no
yes
Lima
2362
yes
no
Orsa
2370
no
yes
Idre
2357
yes
no
Ål
2391
no
no
Nås
2368
yes
no
etc.
Of course, this data is small enough be colored ‘by hand’, but we could easily imagine having 100 features, generating 100 maps.
Coloring a parish through XML
The graphics in an SVG file is defined using XML (which is similar to HTML). This means that just like we can change the color of a webpage in HTML, we can change the color of our linguistic area by changing the style and setting a new ‘fill’ color.
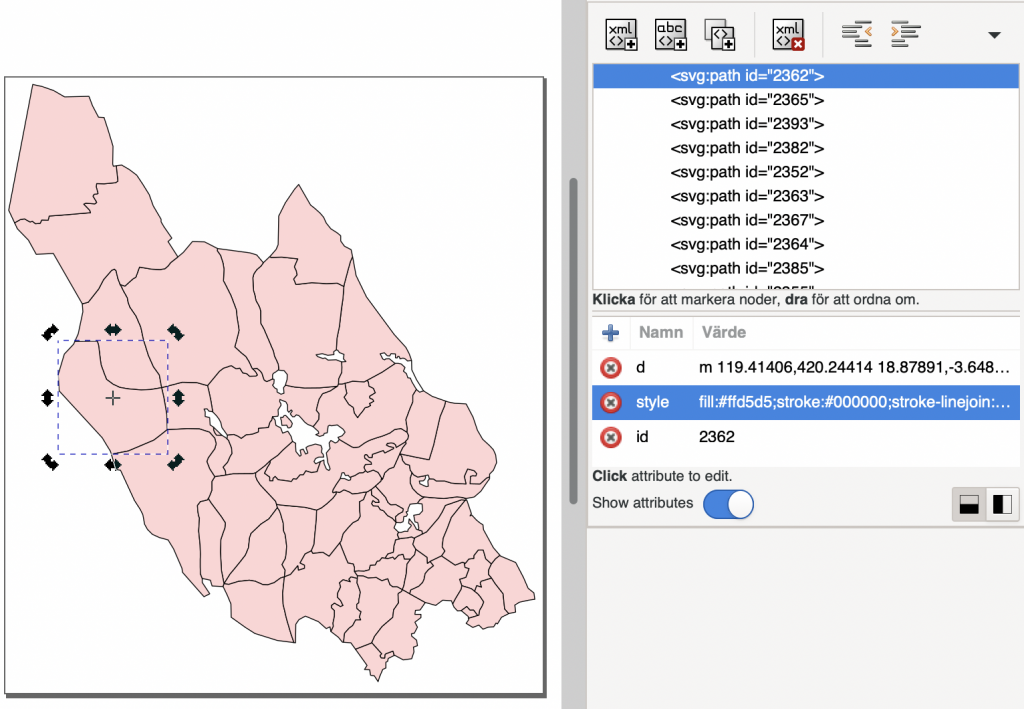
The XML code of an object in Inkscape.
In the screenshot above, I have highlighted the parish of Lima (code 2362), and as you can see it has three attributes.
(1) d, the definition of the path, i.e. the lines and curves of the shape. (2) style, the look of the path, for instance the width of its borders and crucially, the color it is filled with in a hex triplet format, i.e. #ffd5d5 for light pink. (3) id, the ID for the path mentioned above, in this case I chose its parish code as ID, but it could be anything.
Writing the script
Next, we need a script that will change the color of the parish depending on the feature value in our spreadsheet, so that if the value is “yes”, it will change the color to e.g. red, but if the value is “no”, the color will be light orange. If I don’t have the data for a certain parish, I chose gray as a color. My data is binary, but you could set as many colors as you want depending on your value, e.g. red for one etymon, green for another, blue for a third, etc.
The code
We need two packages: xml.etree.ElementTree in order to read the SVG as XML, and pandas in order to work with spreadsheets.
import xml.etree.ElementTree as ET import pandas as pd
tree = ET.parse('dalarna_basemap.svg') root = tree.getroot() ns = "http://www.w3.org/2000/svg"
I then make a list of all the feature columns, and I store the parish codes with the features in a dictionary.
all_features = df.columns[2:].tolist()
df_dict = df.set_index('parish_code').T.to_dict()
This is the final part of the code. For each column (each feature), the code goes through the XML tree and looks for the parish code (the ID). It then looks at the feature column and changes the style of the object by changing the color to #a50f15 (dark red) for “yes”, #fee5d9 (light orange) for “no” and #cccccc (gray) for “no data”. You could add more parameters and colors to this list of course. Finally, I save all the maps in a folder called “maps” with the title “dalarna” followed by the column name.
for i in all_features: for element in root.iterfind("./{%s}g/*" % ns): parish_code = element.attrib['id'] value = df_dict[parish_code][i] if value == 'yes': element.set('style', 'fill:#a50f15;stroke:#000000') if value == 'no': element.set('style', 'fill:#fee5d9;stroke:#000000') if value == 'no data': element.set('style', 'fill:#cccccc;stroke:#000000') tree.write('<my_path>/maps/dalarna_{}.svg'.format(i))
Conclusion
Parishes of Dalarna with h-loss.Parishes of Dalarna with hv-fortition.
Quite easily, I could generate two maps of two phonological features in the dialects of Dalarna, and it would be quite easy to make more by adding more columns.
There are some pitfalls to this method. For instance, it does not capture variation within the parish. Quite often, villages within the same parish will differ from one another. Our method does not really allow us to capture this, for instance by different shades of red.
What we can do is either to create more sub-areas, for instance northern and southern Lima with two different IDs. Another solution is to have one color for parameter a, one for b, and then one color in between a and b for areas that have both.
The part which requires the most work is of course to create the basemap. If you are working with a large area with hundreds of language areas, then creating an SVG basemap is going to take a long time, but so would making every map individually. If you know that you are going to create many maps of this kind using that basemap as a background, then it might be a good investment to create a good high-quality SVG basemap that allows for this kind of manipulation in the future.
Preverbs are a way in which some languages specify various aspects of a verb, e.g. the direction of the action and where it is taking place. The defining characteristic of a preverb is that it precedes the verb it alters, which means that preverbs are usually verbal prefixes. The term preverb is not used for all languages though, but similar constructions are found in many languages and language families across the world. Preverbs can convey quite a wide array of meanings and functions, as they can e.g. indicate the location, direction, tense, aspect (i.e. if an action is completed or ongoing) and negation. It is therefore common for preverbs to convey meanings that are expressed by prepositions and auxiliary verbs in other languages, such as English ‘I’m going in’, ‘I’m going out’ and ‘I will go’. Certain languages have evolved highly sophisticated manners of using preverbs to more or less attach all this information on to the verb. Since I’m working with languages in the Caucasus, I will give some examples from some of the region’s many fascinating languages as preverbs are found in all its three indigenous language families.
A dog resting in the mountainous area of Khevi in Georgia, likely anticipating the next preverb that determines which direction the excursion will take.
Georgian, Megrelian, Laz and Svan belong to the Kartvelian or South Caucasian language family, and they are rather notorious for their preverbs, as they convey a complex combination of direction, tense and aspect (Rostovtsev-Popiel 2016). The original function of preverbs in these languages was to convey the direction and orientation of various actions (Hewitt 1995: 148), e.g. as with the Georgian preverbs mi– ‘thither, there’ and mo– ‘hither, here’.
mi-di-s
there-go-3rd person singular
‘He/she is going there/thither’.
mo-di-s
here-go-3rd person singular
‘He/she is coming here/hither’.
You can even combine these two preverbs to create ‘mi-mo-di-s’, which literally means ‘he/she thither-hither-goes’ and means that someone is coming and going (Hewitt 1995). These can also be combined with at least seven other preverbs in Georgian, which convey meanings such as ‘up’, ‘down’, ‘in’, ‘out’, across’, ‘away’ and ‘down into’ (Hewitt 2005: 29). This means that Georgian can easily construct complex verbs like:
a-mo-di-s
up-here-go-3rd person singular
‘He/she is coming up here/hither’
ga-mo-di-s
out-here-go-3rd person singular
‘He/she is coming out here/hither’.
še-mo-di-s
in-here-go-3rd person singular
‘He/she is coming in here/hither’.
Georgian also uses the same preverbs to differentiate tenses, c.f. these unfortunate examples (Hewitt 1995: 128):
Present tense: v-i-kʼvl-eb-i – ‘I am being killed’.
Future tense: mo–v-i-kʼvl-eb-i – ’I shall be killed’.
Past tense (Aorist): mo–v-i-kʼal-i – ‘I was killed’.
As we can see above, these preverbs do not always express direction, but we will not delve deeper into the somewhat confusing preverbs of Georgian. The neighbouring Northwest Caucasian languages have even more complex preverbs, e.g. Kabardian that is spoken in the Russian autonomous republics of Kabardino-Balkaria (which is home to Europe’s highest mountain, i.e. Mount Elbrus) and Karachay-Cherkessia.
Mount Elbrus, the highest mountain in Europe, is located in the Russian autonomous republic of Kabardino-Balkaria, where the Northwest Caucasian language Kabardian is spoken.
Kabardian preverbs distinguishes de– ‘in’ from xe– ‘in a mass (like water)’ and numerous other further specified orientations like perə– ‘in front of’, ɕʼe– ‘under’, fʼe– ‘in front of, on something vertical (like a wall)’, qʼʷe– ‘behind’, gʷe– ‘next to’, čʼʷecʼə– ‘inside’, ʔʷə– ‘near’, ɕħeɕə– ‘at the tip, above’ and bʁurə– ‘on the side’ (Kumaxov 2013: 201-206). If we use some of these preverbs with the verb t- ‘to stand’ we find how Kabardian express the following meanings (translated from Russian):
de-t-ən – ‘to stand in (something, e.g. a courtyard)’.
perə-t-ən – ‘to stand in front of (something)’.
qʼʷe-t-ən – ‘to stand behind (something)’.
gʷe-t-ən – ‘to stand next to (something)’
ʔʷ–t-ən – ‘to stand near or close to (something)’.
čʼʷecʼə-t-ən – ‘to stand inside (something)’
bʁurə–t-ən – ‘to stand on the side (of something)’
(Kumaxov 2013)
Kabardian also has something that is common in all Northwest Caucasian languages, as they have preverbs that relate to body parts such as ʔepə– ‘to/in/from the hand(s)’, ɕħerə– ‘to/on/from the head’ and ɬə– ‘to/on/from the foot/feet’ (Kumaxov 2013), and the related language Abkhaz has even more preverbs of this type, e.g. çʼa– ‘to/from/in the mouth’, gʷala– ‘to/from/in the heart’ and curiously cʷə– ‘to/from the sun’ (Hewitt 2010: 116-119). This is not as strange as it might seem however, as some Indo-European languages have similar verbal constructions like Swedish handleda ‘supervise (literally ‘to hand-lead’) and munhuggas ‘argue (literally ‘to mouth-stab’ reciprocally) and Latin manufactus ‘hand-made’. This also holds true for direction and location, as there are numerous Indo-European examples such as German ausgehen ‘out-go’, Swedish pågå ‘on-go’, Latin intrōdūco ‘into-lead’ and Russian входить ‘in-go’. Even if these forms are similar to but not conventional preverbs, they clearly appear to be less complicated than the examples given above from Georgian and Kabardian. This ends the introduction and insight into the fascinating world of Caucasian preverbs and I hope that you have not lost neither your direction nor orientation after reading this!
Filip Larsson
References
Hewitt, B. G. (1995). Georgian: A Structural Reference Grammar. London Oriental and African Language Library, volume 2. Amsterdam/Philadelphia: John Benjamins Publishing Company.
Kumaxov, M. A. (2013). Кабардино-черкесский язык. Moskva: Inst. Jazykoznanija, RAN.
Rostovtsev-Popiel, Alexander (2016). ‘Kartvelian Preverbs in Cross-Linguistic Perspective’, VII International Symposium on Kartvelian Studies.
In many languages, English included, there is only one grammatical word class for nouns—namely, nouns. Other languages, however, make more fine-grained distinctions within this category. One of the most common such examples is the division of nouns into two separate classes: alienable and inalienable ones. Alienable nouns can be alienated, i.e., they can stand on their own without any indication of their owner (e.g. a dog). Inalienable nouns, by contrast, cannot be alienated, i.e., their owner must be expressed every time they are used. In other words, inalienable nouns are obligatorily possessed.
Baniwa, an Arawak language spoken in Northwestern Amazonia, is one of the languages which makes this distinction. Alienable and inalienable nouns in Baniwa are formally distinct, which means that they have different inflection patterns and different ways of combining with other words. In example (1a), the inalienable noun -nóma ‘mouth’ is preceded by a hyphen to indicate that it cannot stand alone without its possessor (i.e., one cannot say ‘one mouth’ using this form), whereas the alienable noun tsíino ‘dog’ in (2a) can. In (1b) and (2b), both nouns are shown with a first person singular possessor (‘my X’). Note that while –nóma (1b) simply takes the person marking prefix no-, tsíino (2b) needs to be converted into an inalienable version with the suffix –ni (the * in example (2c) means that the expression is unaccepted by native speakers).
(1) a. -nóma b. nonóma
'(someone's) mouth' no-noma
1sg-mouth
'my mouth'
(2) a. tsíino b. notsínoni c. *notsíino
'dog' no-tsiino-ni no-tsiino
1sg-dog-DPTZ 1sg-dog
'my dog' 'my dog' (intended)
Thus, in Baniwa, alienable nouns can be converted to inalienable ones in order to mark their possessor. But how about the other way around? As it turns out, inalienable nouns can be converted into alienable ones, too. (3a) shows the inalienable noun –eenípe, which means ‘child’ in the sense ‘offspring’, as in ‘my child’ in (3b). In (4), –eenípe has been converted to an independent noun by means of the prefix i– and the suffix –tti, which is necessary for it to be able to stand without a possessor. Interestingly, this conversion process is accompanied by a change in meaning—from ‘offspring’ to ‘young human being’ (which can both be referred to by ‘child’ in English).
(3) a. -eenípe b. noenípe
'(someone's) child (offspring)' no-eenipe
1sg-child
'my child (my offspring)'
(4) ienipétti
i-eenipe-tti
INDL-child-NMLZ
'child (young human being)'
This meaning change illustrates quite well the kinds of nouns which typically fall into the two categories: inalienable nouns typically include kinship relations (like –eenípe) and body part terms (like –nóma). A child, in the sense of ‘young human being’, does not denote a kinship term, but an individual which is not defined by its relationship to any other individual—thus, it makes sense for this meaning to belong to the alienable category.
The alienable/inalienable distinction is found in languages all over the world, but is most common in the Americas.
Sources
Ramirez, H. (2001). Uma Gramática do Baniwa do Içana. Ms.
Ramirez, H. (2001). Dicionário da Língua Baniwa. Manaus: Universidade do Amazonas.
Laughter is universal – all cultures enjoy jokes and laughter. Sometimes we cannot stop ourselves from laughing, even at a bad pun such as “The past, the present and the future walk into a bar… it was tense”. There are even studies showing that laughter therapy can be utilized as one of several ways of treating anxiety and depression. I think most people can agree that laughing is something enjoyable, and even more so if you are laughing with a friend or two. Laughter is so important to us that we have come up with many ways of laughing online, through chats, and the way in which we represent laughter in writing varies across languages.
In English, we have the classic abbreviation lol, ‘laughing out loud’, and its sibling lmao, ‘laughing my ass of’, as well as more onomatopoeic expressions like hahaha. Swedish makes use of the same onomatopoeic expression haha, as well as hehe, but also has an older convention that abbreviated the word “asgarv” (roughly laughing hard’) as asg. It is far less used today as compared to 10 years ago, but at one point it was a common way to show that one is laughing.
Blog posts and discussion forums online lists many different ways of laughing across languages, for example in Spanish, laughter is written jajaja – using the Spanish orthography show the sound of laughing. Russian does the same, laughing by writing xaxaxa, where x is pronounced as /h/. Greek also uses xaxaxa to express laugher, again x is pronounced as /h/. There are also other ways of expressing laughter onomatopoetically, in Thai for example, 555 can be used to write laughter because 5 is pronounced “ha”.
There are different reports of how Japanese speakers type laughter, both wwww and 草 (‘grass’) are said to be used in the language. One explanation that is given is that ‘laugh’ is written with the kanji 笑, pronounced “warai” and which was later shortened to just w. As more laughter was needed, more w’s were added, creating wwwwwwww. Now, stories online tell us that since wwww looks like clusters of grass, the kanji for grass, 草, was jokingly used to represent laughter. There are no reports online on how widespread these different uses are, but it is still interesting to see the creativity of laughing in writing that is shown in these stories.
In the end, despite cross-linguistic differences in how laughter is represented in text, laughter can bring us together and in our digital society we have language-independent ways of expressing laughter: emojis. Whether you are an iOS or an Android user, your laughter can be (somewhat) seamlessly translated using Unicode, and 😂, 😆 or 🤣 will all show you the same emotion – and perhaps emotions are, to some extent, universal to human experience.
Interested in reading more?
About laughter therapy:
Akimbekov, N. S., & Razzaque, M. S. (2021). Laughter therapy: A humor-induced hormonal intervention to reduce stress and anxiety. Current Research in Physiology, 4, 135-138. doi:10.1016/j.crphys.2021.04.002
How to signal sarcasm in writing:
Thompson, D. & Filik, R. (2016). Sarcasm in Written Communication: Emoticons are Efficient Markers of Intention. Journal of Computer-Mediated Communication, 21, pp 105-120. doi:10.1111/jcc4.12156
How to adapt spokenlikeness to writing:
Hård af Segerstad, Y. (2002). Use and Adaptation of Written Language to the Conditions of Computer-Mediated Communication (Doctoral Dissertation). Göteborg: Dept. of Linguistics, Göteborg University. Retrieved from https://gupea.ub.gu.se/handle/2077/15738
More about language use online:
McCulloch, G. (2019). Because Internet: Understanding the New Rules of Language. Riverhead Books.





Comments